Examples for Understanding Task

In this work, we propose ChatVLA, the first work to unify multimodal understanding and embodied control.
Humans possess a unified cognitive ability to perceive, comprehend, and interact with the physical world. Why can't large language models replicate this holistic understanding? Through a systematic analysis of existing training paradigms in vision-language-action models (VLA), we identify two key challenges: spurious forgetting, where robot training overwrites crucial visual-text alignments, and task interference, where competing control and understanding tasks degrade performance when trained jointly.
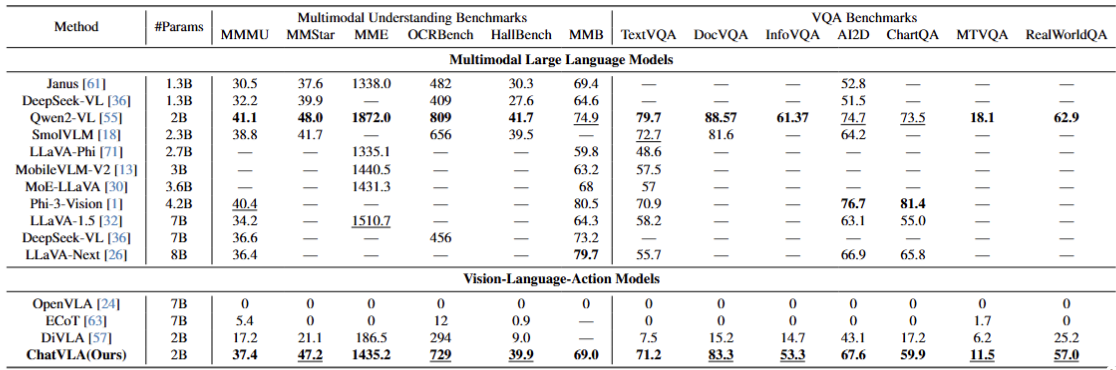
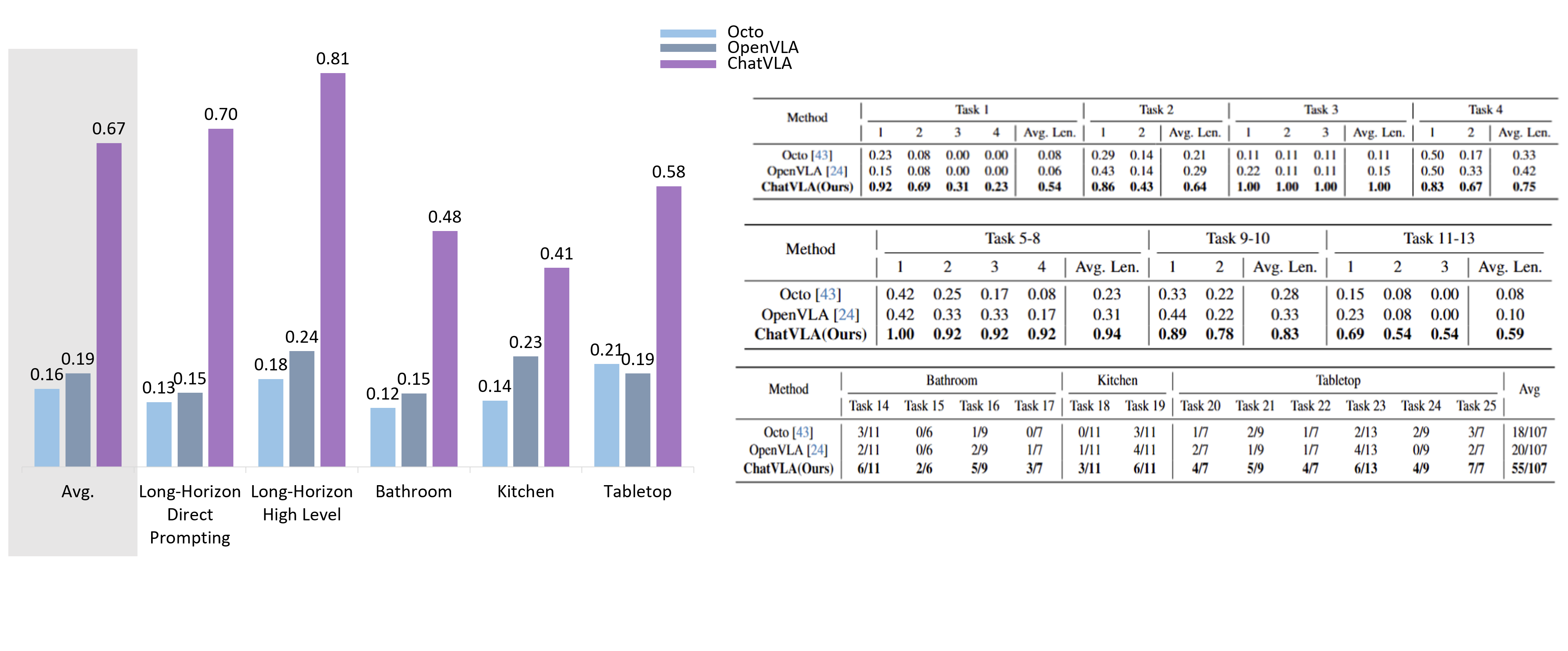
To overcome these limitations, we propose ChatVLA, a novel framework featuring Phased Alignment Training, which incrementally integrates multimodal data after initial control mastery, and a Mixture-of-Experts architecture to minimize task interference. ChatVLA demonstrates competitive performance on visual question-answering datasets and significantly surpasses state-of-the-art vision-language-action (VLA) methods on multimodal understanding benchmarks. Notably, it achieves a six times higher performance on MMMU and scores 47.2 on MMStar with a more parameter-efficient design than ECoT. Furthermore, ChatVLA demonstrates superior performance on 25 real-world robot manipulation tasks compared to existing VLA methods like OpenVLA. Our findings highlight the potential of our unified framework for achieving both robust multimodal understanding and effective robot control.
Below are three examples of long-horizon tasks with direct prompting.
Below are two examples of long-horizon tasks with high-level policy model.
@misc{zhou2025chatvlaunifiedmultimodalunderstanding,
title={ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model},
author={Zhongyi Zhou and Yichen Zhu and Minjie Zhu and Junjie Wen and Ning Liu and Zhiyuan Xu and Weibin Meng and Ran Cheng and Yaxin Peng and Chaomin Shen and Feifei Feng},
year={2025},
eprint={2502.14420},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2502.14420},
}